머신러닝 기초 개념 완벽 정복: 개념부터 활용 사례까지
작성자 정보
- 머신러닝 기초 개념 작성
- 작성일
컨텐츠 정보
- 160 조회
- 목록
본문
| 키워드 | 검색량 | 관련성 |
|---|---|---|
| 머신러닝 기초 | 높음 | 매우 높음 |
| 머신러닝 개념 | 높음 | 매우 높음 |
| 머신러닝 입문 | 높음 | 높음 |
| 머신러닝 예시 | 중간 | 높음 |
| 머신러닝 활용 | 중간 | 높음 |
머신러닝이란 무엇일까요? 간단히 설명해주세요.
머신러닝(Machine Learning)은 인공지능(AI)의 한 분야로, 컴퓨터가 명시적으로 프로그래밍되지 않고도 데이터로부터 학습하고, 패턴을 인식하며, 예측을 수행하는 능력을 의미합니다. 즉, 사람이 직접 규칙을 정의하지 않고, 컴퓨터가 데이터를 통해 스스로 규칙을 찾아내는 것입니다. 예를 들어, 스팸 메일 필터는 수많은 메일 데이터를 학습하여 스팸과 정상 메일을 구분하는 규칙을 스스로 학습합니다. 이러한 학습 과정을 통해 머신러닝 모델은 점점 더 정확한 예측을 할 수 있게 됩니다.
머신러닝의 주요 유형은 무엇이며, 각각의 차이점은 무엇인가요?
머신러닝은 크게 지도 학습, 비지도 학습, 강화 학습 세 가지 유형으로 나뉩니다.
| 유형 | 설명 | 예시 | 장단점 |
|---|---|---|---|
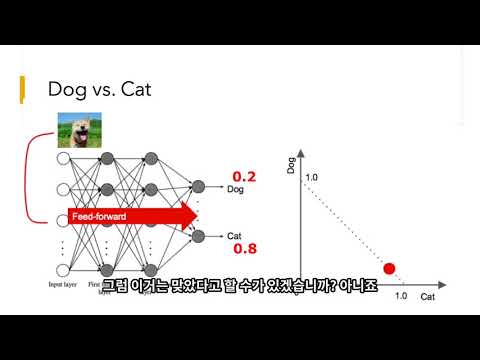
| 지도 학습 (Supervised Learning) | 입력 데이터와 그에 대한 정답 레이블(출력)이 함께 주어지며, 모델은 이를 바탕으로 입력과 출력 간의 관계를 학습합니다. | 이미지 분류 (고양이 사진 vs. 개 사진), 스팸 필터링 | 높은 정확도 달성 가능, 하지만 레이블링된 데이터가 필요 |
| 비지도 학습 (Unsupervised Learning) | 레이블이 없는 데이터로부터 패턴이나 구조를 찾는 학습 방식입니다. | 고객 세분화, 이상치 탐지 | 레이블링 작업이 필요 없음, 하지만 결과 해석이 어려울 수 있음 |
| 강화 학습 (Reinforcement Learning) | 에이전트가 환경과 상호작용하며, 보상을 최대화하는 행동을 학습하는 방식입니다. | 게임 플레이, 로봇 제어 | 복잡한 문제 해결 가능, 하지만 학습 시간이 오래 걸릴 수 있음 |
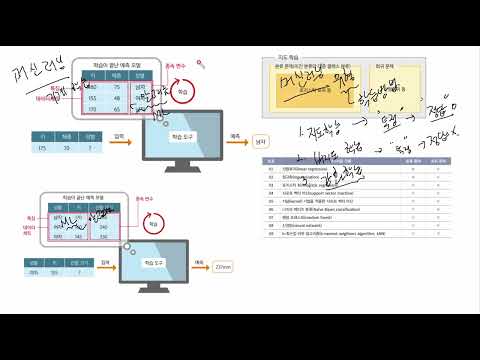
머신러닝 모델은 어떻게 학습하고 평가하나요?

이미지 클릭시 자세한 내용을 확인하실 수 있어요!
머신러닝 모델은 학습 데이터를 이용하여 모델 파라미터(가중치 등)을 조정하며 학습합니다. 학습 과정은 크게 다음과 같은 단계로 이루어집니다.
- 데이터 준비: 데이터 수집, 전처리(결측치 처리, 이상치 제거, 특징 추출 등)
- 모델 선택: 문제 유형에 적합한 모델 선택 (예: 선형 회귀, 로지스틱 회귀, 서포트 벡터 머신, 의사결정 트리, 신경망 등)
- 모델 학습: 선택한 모델에 학습 데이터를 입력하여 모델 파라미터를 조정합니다.
- 모델 평가: 테스트 데이터를 사용하여 모델의 성능을 평가합니다. 평가 지표는 문제 유형에 따라 다르지만, 일반적으로 정확도, 정밀도, 재현율, F1 스코어 등을 사용합니다.
- 모델 배포: 학습된 모델을 실제 서비스에 적용합니다.
머신러닝과 딥러닝의 차이점은 무엇인가요?

이미지 클릭시 자세한 내용을 확인하실 수 있어요!
머신러닝과 딥러닝은 밀접한 관계를 가지고 있지만, 몇 가지 중요한 차이점이 있습니다.
| 특징 | 머신러닝 | 딥러닝 |
|---|---|---|
| 데이터 특징 추출 | 사람이 수동으로 특징을 추출 | 자동으로 특징을 학습 |
| 모델 복잡도 | 상대적으로 단순 | 매우 복잡 (다층 신경망) |
| 데이터 요구량 | 상대적으로 적은 데이터 | 방대한 양의 데이터 필요 |
| 계산 자원 | 적은 계산 자원 | 많은 계산 자원 필요 (GPU) |
머신러닝의 실제 활용 사례는 어떤 것이 있나요?
머신러닝은 다양한 분야에서 활용되고 있습니다.
- 이미지 인식: 자율 주행 자동차, 얼굴 인식 시스템
- 자연어 처리: 챗봇, 기계 번역, 감정 분석
- 추천 시스템: 넷플릭스 영화 추천, 아마존 상품 추천
- 금융: 신용카드 사기 탐지, 주식 시장 예측
- 의료: 질병 진단, 약물 개발
결론: 머신러닝의 미래와 학습 방향

이미지 클릭시 자세한 내용을 확인하실 수 있어요!
머신러닝은 계속해서 발전하고 있으며, 우리 삶의 많은 부분에 영향을 미치고 있습니다. 본 글에서 다룬 기초 개념을 바탕으로 더 깊이 있는 학습을 통해 머신러닝 전문가로 성장할 수 있기를 바랍니다. 온라인 강의, 서적, 실습 프로젝트 등 다양한 학습 방법을 활용하여 실무 경험을 쌓는 것이 중요합니다. 꾸준한 학습과 실험을 통해 머신러닝의 잠재력을 탐색하고, 다양한 문제 해결에 활용할 수 있기를 기대합니다.
출처 : 머신러닝 기초 개념 블로그 머신러닝 기초 개념 정보 더 보러가기
네이버백과 검색 네이버사전 검색 위키백과 검색
머신러닝 기초 개념 관련 동영상







머신러닝 기초 개념 관련 상품검색
관련자료
-
이전
-
다음